
The iBGP Forwarding Problem
BGP is the answer, what was the question? When learning iBGP in the beginning stages of my SP-networking journey, I loved the idea of keeping intelligence at the edge. But, how do you actually do that? Read to find out what I’m talking about!
If you have a seasoned or well-tuned knowledge of iBGP, you can safely proceed to the Problem section and Topology example
Advertise infrastructure addresses and loopbacks in the IGP, and just about everything else advertise into BGP. That’s the motto we follow in SP networking, and possibly in enterprise and definitely data center networking as well. We are not filling our IGPs with customer prefixes, internet routes, and everything but the kitchen sink. It does not scale and is an expensive operation running thousands of routes in the IGP, not to mention a lot of link-state to flood and keep track of.
We know BGP is our swiss army knife protocol of choice, the protocol we love shoving more and more control plane operations into. It’s our bread and butter. By introducing new AFI/SAFI values to BGP the network community has technologies such as L3VPN, L2VPN, VPLS, EVPN, BGP-LS, NG-MPVN and BGP-LU in addition to ipv4 and ipv6 unicast/multicast. For a longer list of AFI/SAFI values and more information I’d like to refer you to this link where you’ll find a plentiful list.
Problem
So… what’s the iBGP Forwarding Problem that the title of this blog refers to? Well, it may or may not be a problem at all when you first rollout iBGP for the first time depending on whether you go with full-mesh sessions among ALL routers. But, it’s critical to understand that it’s something you could run into whether you’re a beginner networker or advanced. When you deploy iBGP in your AS, your core routers still need to know what to do with packets. iBGP intelligence only being kept on the PE’s is great and all, but the core P routers still need to know enough to make forwarding decisions. Enough talking, let me show you the problem through an example.
Topology
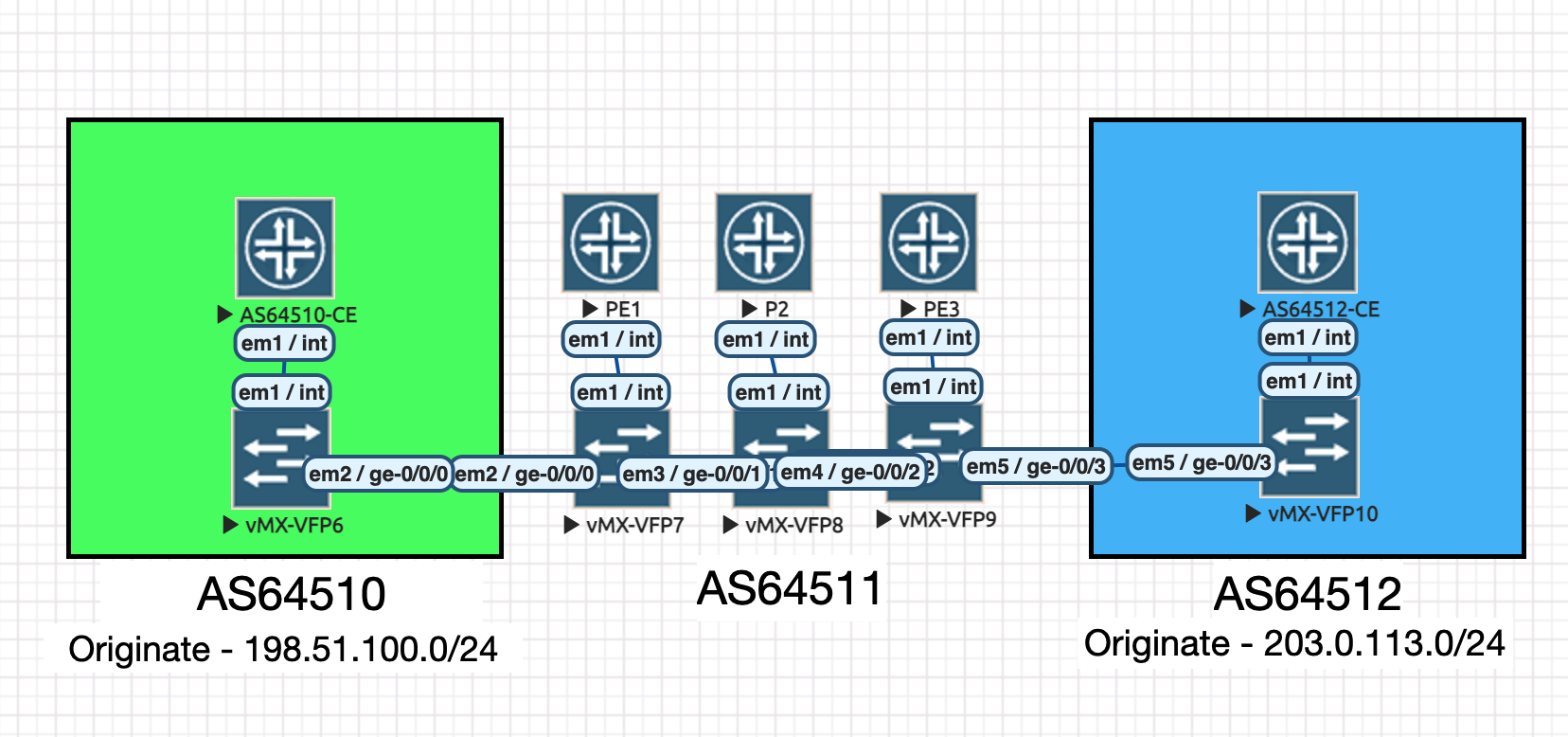
- AS64510 Customer 1
- AS64511 Our Provider network
- AS64512 Customer 2
We are going to accept a BGP prefix from each customer, and advertise it via iBGP between the PEs, and to the other customer. Data forwarding follows the reverse of the flow of advertisements. AS64510 is going to advertise 198.51.100.0/24 and AS64512 is going to advertise 203.0.113.0/24.
PE1 receives the 198.51.100.0/24 prefix from AS64510-CE, and advertises it over the iBGP session to PE3. (By the way, loopback to loopback peering for iBGP sessions. We are using IS-IS as our underlying IGP for reachability)
root@PE1# show route receive-protocol bgp 100.64.0.0
inet.0: 10 destinations, 10 routes (10 active, 0 holddown, 0 hidden)
Prefix Nexthop MED Lclpref AS path
* 198.51.100.0/24 100.64.0.0 64510 I
root@PE1# show route advertising-protocol bgp 192.0.2.3
inet.0: 10 destinations, 10 routes (10 active, 0 holddown, 0 hidden)
Prefix Nexthop MED Lclpref AS path
* 198.51.100.0/24 Self 100 64510 I
So far, so good right? PE3 receives the prefix information for 198.51.100.0/24 and advertises it back out toward 64512-CE.
root@PE3# show route receive-protocol bgp 192.0.2.1
inet.0: 10 destinations, 10 routes (10 active, 0 holddown, 0 hidden)
Prefix Nexthop MED Lclpref AS path
* 198.51.100.0/24 192.0.2.1 100 64510 I
root@PE3# run show route advertising-protocol bgp 100.64.0.7
inet.0: 10 destinations, 10 routes (10 active, 0 holddown, 0 hidden)
Prefix Nexthop MED Lclpref AS path
* 198.51.100.0/24 Self 64510 I
The routes arrive at 64512-CE and I guess we are ready for some pings!
root@AS64512-CE# show route 198.51.100.1
inet.0: 5 destinations, 5 routes (5 active, 0 holddown, 0 hidden)
+ = Active Route, - = Last Active, * = Both
198.51.100.0/24 *[BGP/170] 00:06:04, localpref 100
AS path: 64511 64510 I, validation-state: unverified
> to 100.64.0.6 via ge-0/0/3.0
root@AS64512-CE# run ping 198.51.100.1 source 203.0.113.1
PING 198.51.100.1 (198.51.100.1): 56 data bytes
^C
--- 198.51.100.1 ping statistics ---
3 packets transmitted, 0 packets received, 100% packet loss
Uh oh! That’s not good, failed. Let’s follow the packet from AS64512-CE to AS64510-CE. We know the initial route is pointing from the CE to the PE3 router, so let’s check out the table at PE3.
root@PE3# show route 198.51.100.1
inet.0: 10 destinations, 10 routes (10 active, 0 holddown, 0 hidden)
+ = Active Route, - = Last Active, * = Both
198.51.100.0/24 *[BGP/170] 00:07:44, localpref 100, from 192.0.2.1
AS path: 64510 I, validation-state: unverified
> to 100.64.0.4 via ge-0/0/2.0
Okay, so now we are sending traffic from PE3 toward P2, let’s see what P2 knows about 198.51.100.0/24.
root@P2# run show route 198.51.100.0/24
Ah, ha! P2 knows nothing about the prefix. How can this be? Well, here’s the low-down. We established an iBGP peering between PE1 and PE3, but no peering to P2. By doing this, only PE1 and PE3 know of the routes toward BGP destinations. P2 is completely unaware, and is dropping the traffic to which it knows no route.
Solve the Problem
3 ways to solve this iBGP forwarding problem. Not an exhaustive list, not covering tunneling mechanisms outside of establishing MPLS LSPs
- Configure iBGP peering relationships everywhere (via explicit configuration of all routers to every other router, Route Reflection, or Confederation peerings)
- Use BGP synchronization and make sure that the IGP knows of routes toward BGP destinations (redistribution of BGP into IGP, no thank you)
- Configure BGP-Free Core
1. iBGP Everywhere
Configuring iBGP on P2, and adding the loopback of P2 to the ibgp group on PE1/PE3 (not shown)
root@P2# show | compare
[edit]
+ routing-options {
+ autonomous-system 64511;
+ }
[edit protocols]
+ bgp {
+ group ibgp {
+ type internal;
+ local-address 192.0.2.2;
+ neighbor 192.0.2.1;
+ neighbor 192.0.2.3;
+ }
+ }
After doing so, we revisit the pings from CE to CE and find success
root@AS64512-CE# run ping 198.51.100.1 source 203.0.113.1
PING 198.51.100.1 (198.51.100.1): 56 data bytes
64 bytes from 198.51.100.1: icmp_seq=0 ttl=61 time=6.872 ms
64 bytes from 198.51.100.1: icmp_seq=1 ttl=61 time=6.464 ms
64 bytes from 198.51.100.1: icmp_seq=2 ttl=61 time=7.538 ms
root@P2# run show route 198.51.100.0/24
inet.0: 9 destinations, 9 routes (9 active, 0 holddown, 0 hidden)
+ = Active Route, - = Last Active, * = Both
198.51.100.0/24 *[BGP/170] 00:01:08, localpref 100, from 192.0.2.1
AS path: 64510 I, validation-state: unverified
> to 100.64.0.2 via ge-0/0/1.0
Now, I’m going to rollback 1 that configuration on P2 and we will move onto the 2nd option of solving the iBGP forwarding problem
2. BGP synchronization - NOT RECOMMENDED!
For this to work, we need P2 to know about the BGP destinations inside of the IGP (IS-IS). We do this by redistributing the eBGP-learned prefixes into IS-IS via export policy. Also, note that I changed the preference of the iBGP-learned routes to make sure they were lower than the IS-IS learned external routes
root@PE1# show | compare
[edit policy-options]
+ policy-statement bgp-to-isis {
+ from {
+ protocol bgp;
+ route-filter 198.51.100.0/24 exact;
+ }
+ then accept;
+ }
[edit protocols isis]
+ export bgp-to-isis;
[edit protocols bgp group ibgp]
+ preference 164;
root@PE3# show | compare
[edit policy-options]
+ policy-statement bgp-to-isis {
+ from {
+ protocol bgp;
+ route-filter 203.0.113.0/24 exact;
+ }
+ then accept;
+ }
[edit protocols isis]
+ export bgp-to-isis;
[edit protocols bgp group ibgp]
+ preference 164;
Again, pings work and P2 has a route toward the BGP destinations for forwarding.
root@AS64512-CE# run ping 198.51.100.1 source 203.0.113.1
PING 198.51.100.1 (198.51.100.1): 56 data bytes
64 bytes from 198.51.100.1: icmp_seq=0 ttl=61 time=7.642 ms
64 bytes from 198.51.100.1: icmp_seq=1 ttl=61 time=6.434 ms
64 bytes from 198.51.100.1: icmp_seq=2 ttl=61 time=5.344 ms
root@P2# run show route 198.51.100.0/24
inet.0: 9 destinations, 9 routes (9 active, 0 holddown, 0 hidden)
+ = Active Route, - = Last Active, * = Both
198.51.100.0/24 *[IS-IS/165] 00:02:19, metric 20
> to 100.64.0.2 via ge-0/0/1.0
Please note that method #2 will not scale, as your IGP won’t be able to handle the amount of prefixes you’ll be learning and working with in a real environment. This is an outdated method of “fixing” the iBGP forwarding problem. Let’s move onto something more scaleable, because all this redistribution has me feeling guilty.
rollback 1, commit, and proceed
3. BGP-Free Core
My favorite of the three options, the best of both worlds. You get you have your cake and eat it too. We are only going to establish iBGP between PE1 and PE3. The method of forwarding BGP traffic from PE1 to PE3 is going to be achieved by using MPLS LSPs. P2 is turning into a MPLS-switching router.
Note - Make sure you’ve enabled RSVP and MPLS procols and families.
root@PE1# show protocols mpls
label-switched-path to-pe3 {
to 192.0.2.3;
}
interface all;
root@PE1# run show mpls lsp
Ingress LSP: 1 sessions
To From State Rt P ActivePath LSPname
192.0.2.3 192.0.2.1 Up 0 * to-pe3
Total 1 displayed, Up 1, Down 0
Egress LSP: 1 sessions
To From State Rt Style Labelin Labelout LSPname
192.0.2.1 192.0.2.3 Up 0 1 FF 3 - to-pe1
Total 1 displayed, Up 1, Down 0
root@PE1# run show route table inet.3
inet.3: 1 destinations, 1 routes (1 active, 0 holddown, 0 hidden)
+ = Active Route, - = Last Active, * = Both
192.0.2.3/32 *[RSVP/7/1] 00:01:11, metric 20
> to 100.64.0.3 via ge-0/0/1.0, label-switched-path to-pe3
root@PE3# run show route table inet.3
inet.3: 1 destinations, 1 routes (1 active, 0 holddown, 0 hidden)
+ = Active Route, - = Last Active, * = Both
192.0.2.1/32 *[RSVP/7/1] 00:01:48, metric 20
> to 100.64.0.4 via ge-0/0/2.0, label-switched-path to-pe1
A set of unidirectional LSPs is established. So, what’s this have to do with forwarding BGP traffic? Well, the inet.3 table is used for recursive BGP next-hop lookups as well as inet.0. The RSVP or LDP learned LSP routes are more prerfeable than IGP learned routes, so we use the LSP for forwarding. By default BGP traffic is the only traffic that uses the LSPs for forwarding in JunOS. (This can be customized)
Route table from PE3 to AS64510-CE prefix:
root@PE3# run show route 198.51.100.1 detail
inet.0: 10 destinations, 10 routes (10 active, 0 holddown, 0 hidden)
198.51.100.0/24 (1 entry, 1 announced)
*BGP Preference: 170/-101
Next hop type: Indirect, Next hop index: 0
Address: 0xc387d5c
Next-hop reference count: 2
Source: 192.0.2.1
Next hop type: Router, Next hop index: 584
Next hop: 100.64.0.4 via ge-0/0/2.0, selected
Label-switched-path to-pe1
Label operation: Push 299776
Label TTL action: prop-ttl
Load balance label: Label 299776: None;
Label element ptr: 0xd7cc238
Label parent element ptr: 0x0
Label element references: 2
Label element child references: 0
Label element lsp id: 2
Session Id: 0x140
<mark> Protocol next hop: 192.0.2.1</mark>
Indirect next hop: 0xc2d0d84 1048574 INH Session ID: 0x142
State: <Active Int Ext>
Local AS: 64511 Peer AS: 64511
Age: 21:47 Metric2: 20
Validation State: unverified
ORR Generation-ID: 0
Task: BGP_64511.192.0.2.1
Announcement bits (3): 0-KRT 3-BGP_RT_Background 4-Resolve tree 4
AS path: 64510 I
Accepted
Localpref: 100
Router ID: 192.0.2.1
Protocol next-hop of 192.0.2.1 was recursively resolved using inet.3 and the LSP was found for forwarding. Let’s see now what P2 does upon receiving the label 29976
root@P2# run show route label 299776 detail
mpls.0: 10 destinations, 10 routes (10 active, 0 holddown, 0 hidden)
299776 (1 entry, 1 announced)
*RSVP Preference: 7/1
Next hop type: Router, Next hop index: 584
Address: 0xc38807c
Next-hop reference count: 2
<mark>Next hop: 100.64.0.2 via ge-0/0/1.0, selected
Label-switched-path to-pe1
Label operation: Pop</mark>
Load balance label: None;
Label element ptr: 0xd7dc018
Label parent element ptr: 0x0
Label element references: 2
Label element child references: 0
Label element lsp id: 0
Session Id: 0x140
State: <Active Int AckRequest Accounting EL-capable>
Age: 18:39 Metric: 1
Validation State: unverified
Task: RSVP
Announcement bits (1): 1-KRT
AS path: I
299776(S=0) (1 entry, 1 announced)
*RSVP Preference: 7/1
Next hop type: Router, Next hop index: 585
Address: 0xc387eec
Next-hop reference count: 2
<mark> Next hop: 100.64.0.2 via ge-0/0/1.0, selected
Label-switched-path to-pe1
Label operation: Pop </mark>
Load balance label: None;
Label element ptr: 0xd7dbff0
Label parent element ptr: 0x0
Label element references: 1
Label element child references: 0
Label element lsp id: 0
Session Id: 0x140
State: <Active Int AckRequest Accounting EL-capable>
Age: 18:39 Metric: 1
Validation State: unverified
Task: RSVP
Announcement bits (1): 1-KRT
AS path: I
This router is called the Penultimate-Hop Popping router (PHP), meaning before the egress router the label will be popped and sent to the egress router unlabeled. Configuring explicit-null would change this behavior and a label of 0 would be delivered to the egress PE. The S=0 in the second entry is the S-bit, bottom of stack bit. S is set to 1 when the label is the bottom of stack label, and S is set to 0 when the label is not the bottom label in the stack. This aids in EtherType framing of the ethernet header and forwarding.
At PE3, the router looks at its inet.0 table because the packet was received unlabeled and sends the packet addressed for 198.51.100.1 toward AS64510-CE.
Pros and Cons of each option of the 3 we covered for solving the iBGP forwarding problem -
- iBGP Everywhere
- Pros: No redistribution necessary from BGP->IGP, Every iBGP router can act as a PE down the road
- Cons: Admin overhead of configuring more iBGP neighbors (Reflection helps but still overhead per RR neighbor and RR config)
- BGP Synchronization
- Pros: No need to configure iBGP on intermediate core routers
- Cons: Does not scale well, IGP will become overloaded and convergence will slow eventually
- BGP-Free Core
- Pros: No need to configure iBGP on intermediate routers, possibly no licensed BGP needed for core routers, core routers have a simple job swapping/poppping labels and forwarding packets based off of LIB
- Cons: Must configure MPLS on all routers, Must have MPLS licensing to configure MPLS